

ABD’deki öğrencilik yıllarında önce kriptografi (şifre bilimi) konusuna merak saran von Ahn, ilginç görünmeyen bir dosyanın (örneğin bir resmin) içine üçüncü kişilerin varlığını bile fark edemeyecekleri önemli başka bir mesajı gömerek haberleşme anlamına gelen “steganografi” tekniğinin kullanımı üzerine önemli kuramsal katkılar koyan birkaç çalışmada yer aldı. Kuramsal bilgisayar biliminin devlerinden Venezuelalı Manuel Blum’un danışmanlığında yaptığı doktora tezi sırasındaysa büyük ün kazanmasına yol açacak “insan hesaplaması” kavramını keşfetti.
İnsan hesaplaması, kısaca “yapay zekânın tersi” diye tarif edebileceğimiz harika bir fikir. Malum, yapay zekâ projesinde insan zekâsıyla yapılabilen her işi bilgisayarlara da, mümkünse insanlardan da üstün performansla, yaptırmayı hedefliyoruz.
Ama halen bazı konularda insanlar bilgisayarlardan daha iyi. İnsan hesaplaması, bilgisayarların işte böyle, kendilerine zor gelen bir işle karşılaştıklarında o işi insanlara yaptırması demek. Von Ahn önce (bilgisayarların görüntü tanıma yeteneğinin şimdikinden çok daha geri olması nedeniyle o zaman için iyice kritik olan) “resim etiketleme” (verilen bir resmi tarif eden kelimeleri bulma) işini insanlara bedavaya yaptırmanın bir yolunu buldu. Çözüm, bu işi İnternet üzerinden oynanabilen bir oyun haline getirmekti: İnsanlar kendilerine gösterilen resimleri başka oyuncuların nasıl tarif edeceğini doğru tahmin ederlerse puan kazanıyorlardı. Böylece resim arama motorlarının ve yapay öğrenme algoritmalarının gereksindiği bol miktarda etiketli veri elde edilebiliyordu.
CAPTCHA sistemi
Von Ahn’ın bir sonraki buluşu, yakın zamana dek bazı İnternet sitelerine girerken karşınıza çıkan “şu resimdeki eciş bücüş yazılmış harfler nelerdir?” sorularını oluşturan CAPTCHA sistemi oldu. Sitelerin insan kullanıcıları otomatik yazılımlardan ayırt etmek (ve böylece “robot”ların sözgelimi sitede satılan biletlerin tümünü hızla satın alıp sonra da karaborsaya düşürmesini engellemek) için kullandıkları CAPTCHA büyük bir ekonomik getiri sağlıyor, ama her gün milyonlarca insanın birkaç saniyesini boşa harcamasına yol açtığını hesaplayarak suçluluk duygusuna kapılan von Ahn’ın beyni boş durmuyordu. 2007’de siteye giriş izni alabilmek için bir değil, iki tane eciş bücüş kelimeyi çözüp yazmanızı gerektiren reCAPTCHA devreye girdi. reCAPTCHA tam bir “bir taşla iki kuş vurma” şaheseriydi.
Kağıda basılı kitapların tümünün dijital ortama aktarılması, böylece dünyanın her yerinden isteyen herkesin herhangi bir kitaptaki herhangi bir cümleye arama motoruyla erişebilmesi hedefleniyordu. Bin bir türlü karışık yazı tipi kullanılmış, raflarda yıpranmış eski kitapların bu amaçla taranması sırasında bazı kelimeler otomatik sistem tarafından tanınamıyordu. İşte reCAPTCHA bu çözme işini insanlara yaptırıyordu.
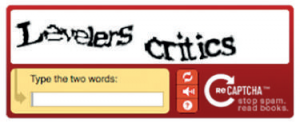 Şekilde görüldüğü gibi, reCAPTCHA kullanan bir siteye girmeye çalıştığınızda size bir değil, iki CAPTCHA sorusu soruluyordu. Bunlardan biri, orijinal CAPTCHA’daki gibi, bilgisayarın zaten cevabını bildiği bir soruydu. Diğeri ise dijitalleştirilmesi istenen bir kitaptan çıkartılıp CAPTCHA formatına büründürülmüş bir kelime görüntüsüydü, yani bu ikinci sorunun yanıtını bilgisayar bilmiyordu. Kullanıcının iki haneyi de gördüğü kelimelerle doldurması isteniyordu. Cevabı bilgisayarca bilinen soru doğru cevaplanırsa siteye giriş izni veriliyor, diğer soruya verilen yanıt ise aynı sorunun sorulduğu başka kullanıcıların verdiği yanıtlarla karşılaştırılıyordu. Birkaç kişi yanlış yapsa da genelde ezici çoğunluk doğru yanıtı gireceği için bu analiz sonucu kitaptaki kelime başarıyla dijitalleştirilmiş oluyordu!
Şekilde görüldüğü gibi, reCAPTCHA kullanan bir siteye girmeye çalıştığınızda size bir değil, iki CAPTCHA sorusu soruluyordu. Bunlardan biri, orijinal CAPTCHA’daki gibi, bilgisayarın zaten cevabını bildiği bir soruydu. Diğeri ise dijitalleştirilmesi istenen bir kitaptan çıkartılıp CAPTCHA formatına büründürülmüş bir kelime görüntüsüydü, yani bu ikinci sorunun yanıtını bilgisayar bilmiyordu. Kullanıcının iki haneyi de gördüğü kelimelerle doldurması isteniyordu. Cevabı bilgisayarca bilinen soru doğru cevaplanırsa siteye giriş izni veriliyor, diğer soruya verilen yanıt ise aynı sorunun sorulduğu başka kullanıcıların verdiği yanıtlarla karşılaştırılıyordu. Birkaç kişi yanlış yapsa da genelde ezici çoğunluk doğru yanıtı gireceği için bu analiz sonucu kitaptaki kelime başarıyla dijitalleştirilmiş oluyordu!
Bu sistemin kullanımda olduğu sürede her gün kırk milyon kelimenin işlendiği hesaplanmış. New York Times gazetesinin tüm eski sayıları ve Google’un çevrimiçi kütüphanesindeki birçok kitap bu şekilde dijitalleştirilmiş. İnsanlar o birkaç saniyeyi harcayarak çok faydalı bir işe katılmış olmuşlar.
Fark etmişsinizdir; reCAPTCHA son birkaç yılda şekil değiştirdi. Yapay zekâdaki hızlı gelişme nedeniyle bilgisayarların örüntü tanımadaki başarı oranı iyileştikçe yukarıdaki senaryodaki testler giderek zorlaştırıldı, YZ bu işlerde insanüstü seviyeye gelince de test fikri bir yana bırakılıp bağlantıyı kurmaya çalışan İnternet adresinin “itibarını” ölçen başka algoritmalar kullanılmaya başlandı. İnsan hesaplaması fikriyse yapay öğrenme algoritmalarına örnek girdi hazırlamak için binlerce resmi etiketlemek gibi sıkıcı işleri (biraz para karşılığında) insanlara yaptırabildiğiniz Amazon “Mekanik Türk” servisi gibi “pazar yerleri”nde yayılarak yaşıyor.
Cem Say / sayster@gmail.com
*Bu yazı HBT’nin 168. sayısında yayınlanmıştır.